1. 现状概览
1.1 无门槛入门指引
1.1.1 时间序列
监控,是对我们所关注系统的特定指标的持续观测、记录以及展示。单次的观测(常常称之为 sample,采样)至少能获取到该指标的一个值,并同时记下这次观测发生的时间点,组成 (Time, Value) 这样的一对记录。持续的记录意味着这对数据在时间这一维度上的延伸——新的 (Time, Value) 数据对被不断添加到记录的末尾,其中 Time 的值不断递增(可能等距或不等距),而 Value 作为该指标的观测结果被不断更新。
如果只是将记录的数据列成表格,除了方便查阅被记录的数值,并无太多优势。为了清晰地展示该指标在某个历史区间随时间的变化趋势,将其绘成图表是更好的选择。
1.1.2 直方图
然而,并非所有指标都能简单地用一个值来表示。有些指标会在一个时刻(或者远远短于观测间隔的一小段连续时间内,从观测这视角看近似于一个点)产生大量的值。完整地将每个值都堆积在记录中是很沉重的负担且没什么意义,将它们适当地聚合会更加易于处理,甚至更凸显指标的特征。
一种通用的方案是额外添加一些划分数据的“桶”(bucket),这些桶互不重叠(互斥)但能完整覆盖该指标可能出现的所有值(完备)。此时我们将不再记录观测到的每个指标数值,而是根据观测到的值将它归入正确的桶中。鉴于前面提到的桶的互斥性与完备性,有且只有一个桶能够收入一个特定的观测值。这样一来,我们需要记录的指标变成各个桶内计进来的观测次数。这种类型的指标我们称之为直方图 (histogram)。
在实际的监控业务中,直方图更倾向于以 le 为参数来给出。le 即是桶的边界,但对应的值是小于等于该边界的所有桶内的累计值而非单个桶内的值。这样的设定与上面的描述可以等价转换,但被许多监控系统默认采用。
1.1.3 直方图与时间序列的关系
注意,时间序列和直方图并非两种互相独立的指标类型,直方图是时间序列的一种特殊形式——它仍然具备随时间更新的特点,只是存在额外的参量 le。
1.2 Grafana 的监控策略与效果
1.2.1 导言
Grafana 是一个功能完善的监控可视化解决方案。Grafana 将一个监控可视化流程分成 datasource 和 panel 两个相互解耦的部分,datasource 负责与不同类型的时间序列数据库 (TSDB) 打交道——TSDB 是指标数据被采集和高效存储的地方,在可视化流程中只需通过 datasource 按合适的方式获取数据即可,无需关注背后的细节。Grafafa 内置了许多种类的 panel,提供了不同的可视化 (visualization) 效果,其中 timeseries panel 是以折线图展示时间序列类型数据的通用方案。
对大多数普通的时间序列而言,timeseries panel 内的功能集都能给出足够优秀的展示效果。然而,考虑直方图类型的数据,简单地使用 timeseries panel 会存在一些问题。通常一个直方图的 le 有很多值,每个值都画出一条曲线会使得图表拥挤不堪。而即使 le 的数量在可接受的范围或者人为地选取其中部分,le 也难以向图表的用户传达出清晰直观的信息——某个指标小于等于特定值的样本有多少个,并不是大多数人关心的问题。
为了给直方图提供更优秀的可视化效果,以 Prometheus 为例,一种常见的方案是利用 histogram_quantile() 函数,将原来表示绝对计数的直方图数据转化为一组百分位数 (percentiles)——在样本中依序排名为特定百分比的原指标值是多少,即常常称之为 Pxx (percentile=xx, xx=1, 2, …, 99) 这样的间接指标。
1.2.2 不足
在很多监控场景下,百分位数确实是用户关心的指标。选取几个恰当的百分位数(常常是 P50, P90, P95, P99 这些),用 timeseries panel 绘制出来,可以很方便地观察单个百分位数的走势。但也仅限于此了——如果还想获取到该指标更完整的值分布信息,会很困难。比如它是更多地聚集在低值区,还是分布得比较均匀,甚至是否具有阶梯式的分布特征,通过几个固定的分位数几乎不可能获取到这样细致的特征信息。
再次强调,很多场景下 P50, P90, P95, P99 确实是用户最关心的指标。因此我们不能单为了展示更完整的分布信息把 P01, P02, …, P99 这些百分位数全部绘制到图表中。这只会使得图表拥挤不堪并把几个最关心的指标淹没下去。
精心选取合适的间隔,绘制一组等间隔的百分位数,虽然能通过类似等高线的方式向观测者提供相对更细致的分布信息,但仍然很不直观,且对观测者提出了更高的理解能力要求。
2. 问题分析
上述方案的问题根源在于,timeseries panel 是一个展示一维信息的体系,时间是这个体系里唯一主要的自变量。而直方图本身包含二维的信息,除了时间以外,还有 le 这个维度。选取一个特定的百分位数计算出来,只相当于选出了 le 这个维度上的一个点(百分位数的计算结果要么刚好是对应时间点上的某个 le,要么是某两个连续 le 的中间值)。timeseries panel 里虽然能上下堆砌几个 P50, P90 等等,但也只是简单的罗列,而非像“时间”那样给出了一个完整的“轴”。要想完整地呈现值分布信息,我们需要额外的“空间”,来绘出 percentile 这根“轴”来。
3. 改进目标
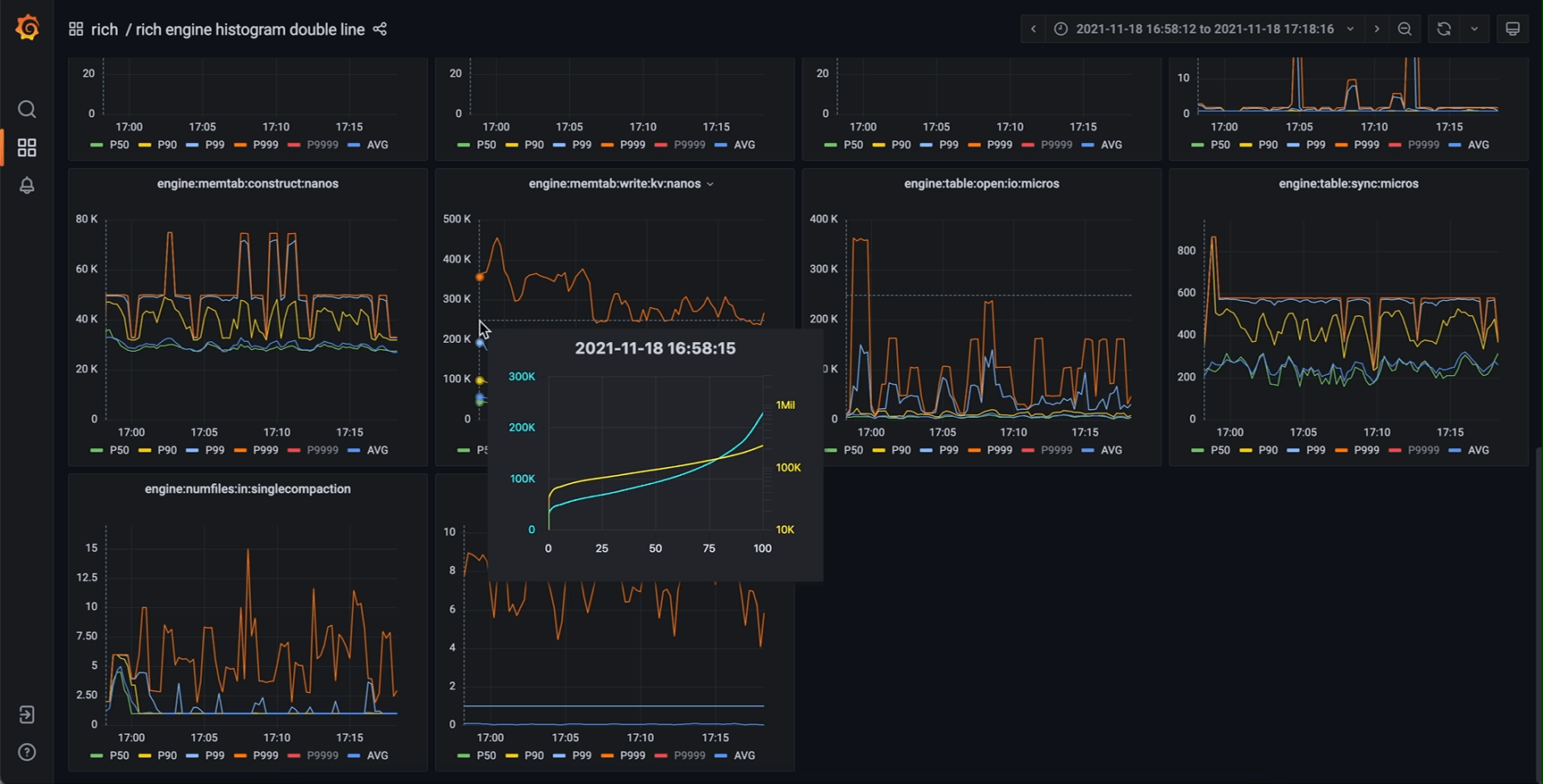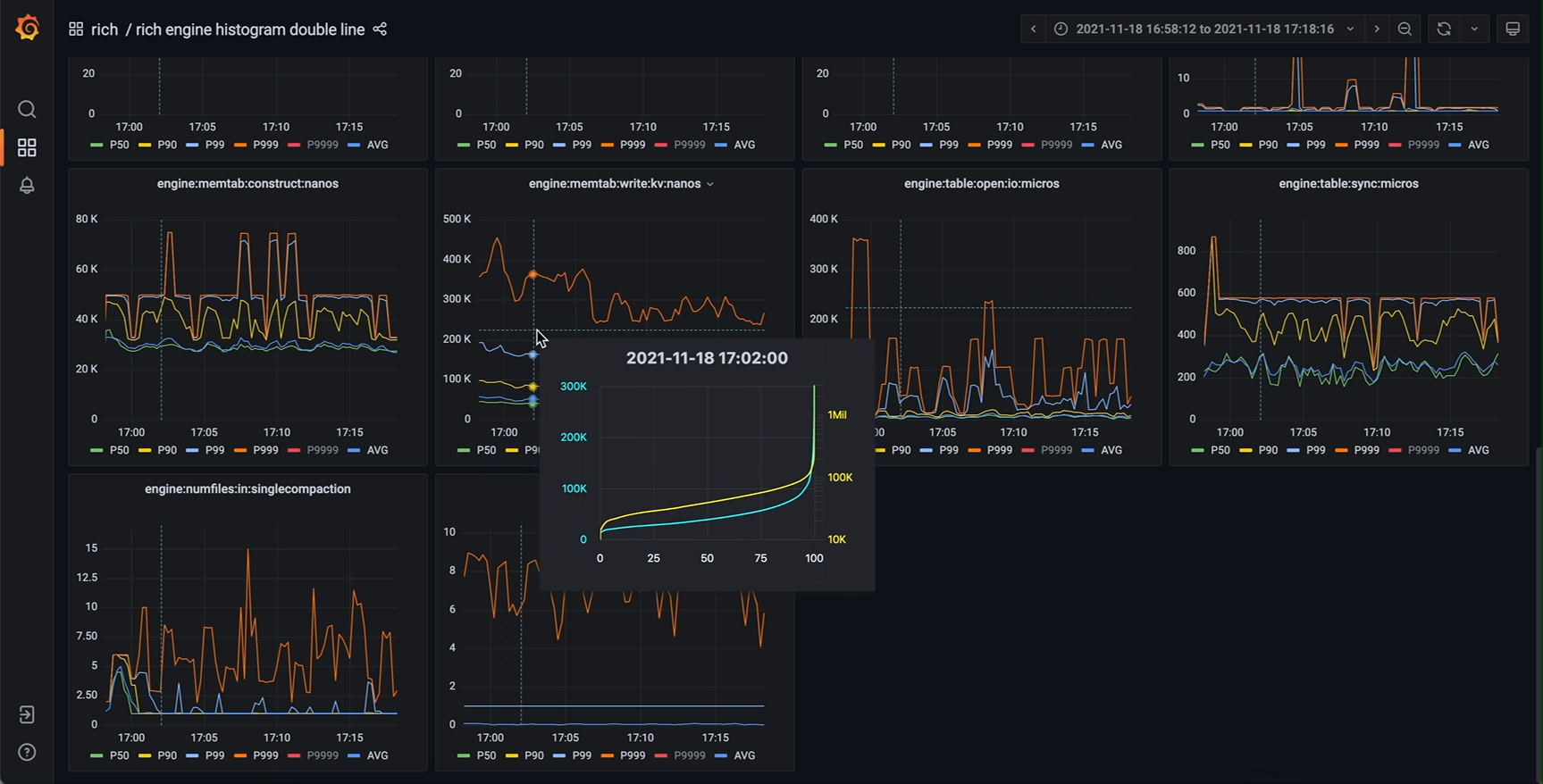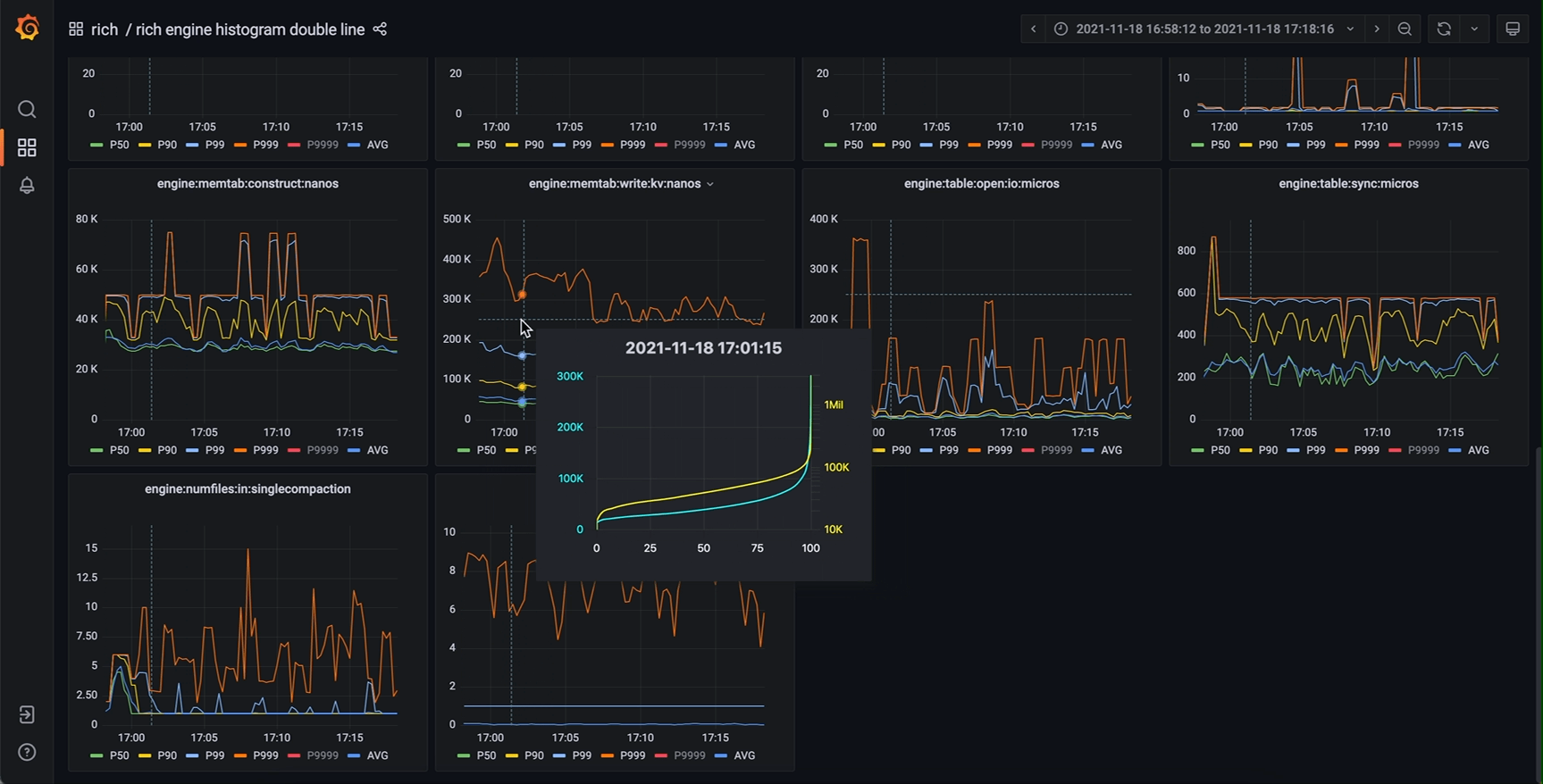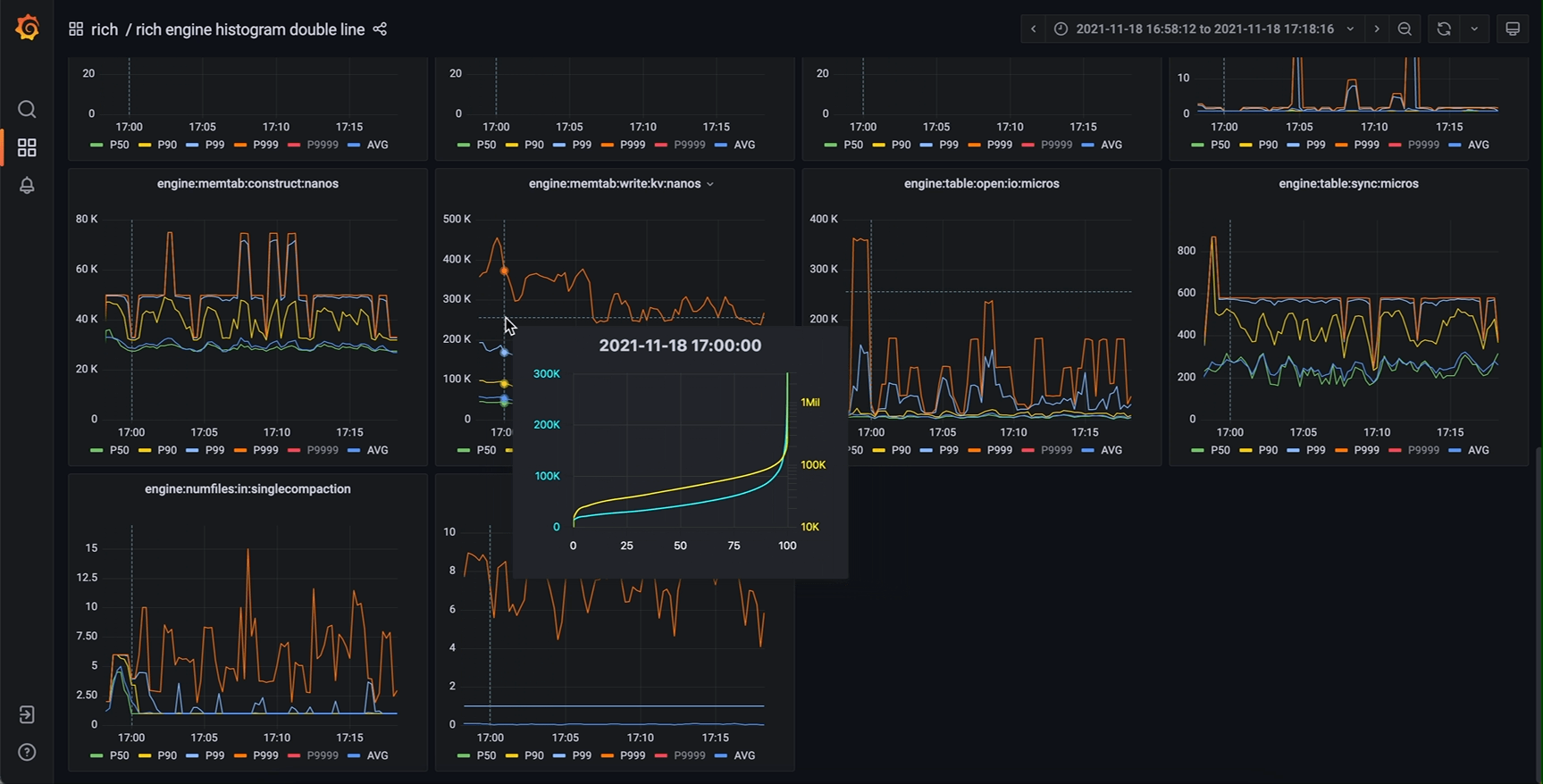
那么 timeseries panel 里还有哪有空间能放下这根新的轴呢?我们注意到,timeseries panel 中存在一个 tooltip (工具提示) 组件。这个 tooltip 原本的功能是在鼠标划过图表区域时弹出一提示框,其中包含图中曲线在鼠标所指时刻的详细数值,可选显示所有曲线的数值或者鼠标最近处曲线的数值。而仔细思考就能发现,我们要展示的完整信息正是现在 tooltip 中信息的超集。那么进一步就能想到,完全可以把这个 tooltip 中的数值表格替换为一张新的图表(不妨称之为 tooltip-chart,次级图表),其 x 轴为正是我们要新加的 percentiles (P00 ~ P100) 或者 quantiles (0.00 ~ 1.00),而 y 轴与主图表相同(因为是同一个指标量)。
作为鼠标所指时刻的信息扩充,新设计的 tooltip-chart 相当于原数据集垂直于时间维度的横切面,能展示最完整的值分布信息的同时,保留了原主图表的所有优势,几个特别关心的 percentiles (P50, P90 等等) 仍然是主图表的主角,清晰地展示它们分别随时间的变化。将鼠标悬停在我们关心的时间点上,我们既能从 tooltip-chart 中看到主图上未绘制出的某个 percentile,也能清晰直观地看出整体的分布特征。对于直方图数据的展示来说,这应当是一个非常惊人的改进效果。
4. 实现思路
当前版本的 Grafana (8.2.x) 使用 React 框架来实现各种不同的 panel。每个 panel 实际上是内部定义的类 PanelPlugin 的一个实例。PanelPlugin 的构造函数允许传入一个 React 组件,该组件中即封装了关于可视化的主要实现细节(该组件保存在实例的 .panel 属性中)。
Grafana 内置的各种 panel 的入口位于一组目录下各自的 module.ts 文件中,我们找到 timeseries panel 对应的 module.ts 文件,即可开始尝试对它进行定制。
进一步考察可知,实现该 panel 的整个组件是一簇层次分明的组件树,组件树的根结点是 TimeSeriesPanel,即 .panel 属性直接所指的组件。timeseries panel 的各个逻辑可分的部分,均由根结点直接或间接地渲染而出。主图表的渲染节点位于组件树中接近根的位置,而 tooltip 的渲染节点位于主图表下更深的层次(子孙节点)。各渲染节点所需数据大抵由根节点传入并沿组件树逐层向下传递。
这样的设计为整个可视化带来了清晰的结构和。原则上,只要能替换或增强 tooltip 的实现,并保持其与上下渲染节点的接口兼容性,我们就能够对 tooltip 中显示的内容进行自定义,包括替换成我们需要的次级图表。
但事实上问题并没有这么简单。在上面这样的设计里,tooltip 作为主图表的一个子节点,它获取到的数据只能是主图表的一个子集!这与我们的需求产生了根本性的冲突——我们希望能在鼠标所指时间点上,在 tooltip 中展示出比主图表更加详细的信息(超集)。
为了比较简单的解决这个问题,一个思路是在局部可控的范围内,绕过 Grafana 预定的数据传递与处理流。事实上,Grafana 内虽然大部分数据是逐层传递的,但也存在少部分会跨层传递,一般是一些比较简单的参数,由顶层提供但只需要被底层某个节点使用,这样的参数绕过中间节点进行传递会更加清晰。
简明起见,这里暂不详谈 Grafana 是如何实现绕过中间节点传递数据的。我们只需知道,只要能找到主图与 tooltip 一个拥有最大数据量的共同祖先节点,我们就能通过这个祖先节点上述两个节点分别传递数据,而非让 tooltip 的数据仅仅来自于主图表这个上游,这样一来,问题就存在简单的可解性了。
5. 实现效果
Grafana 原始的 timeseries panel 可提供如下效果

相同的监控系统,改进后效果如下
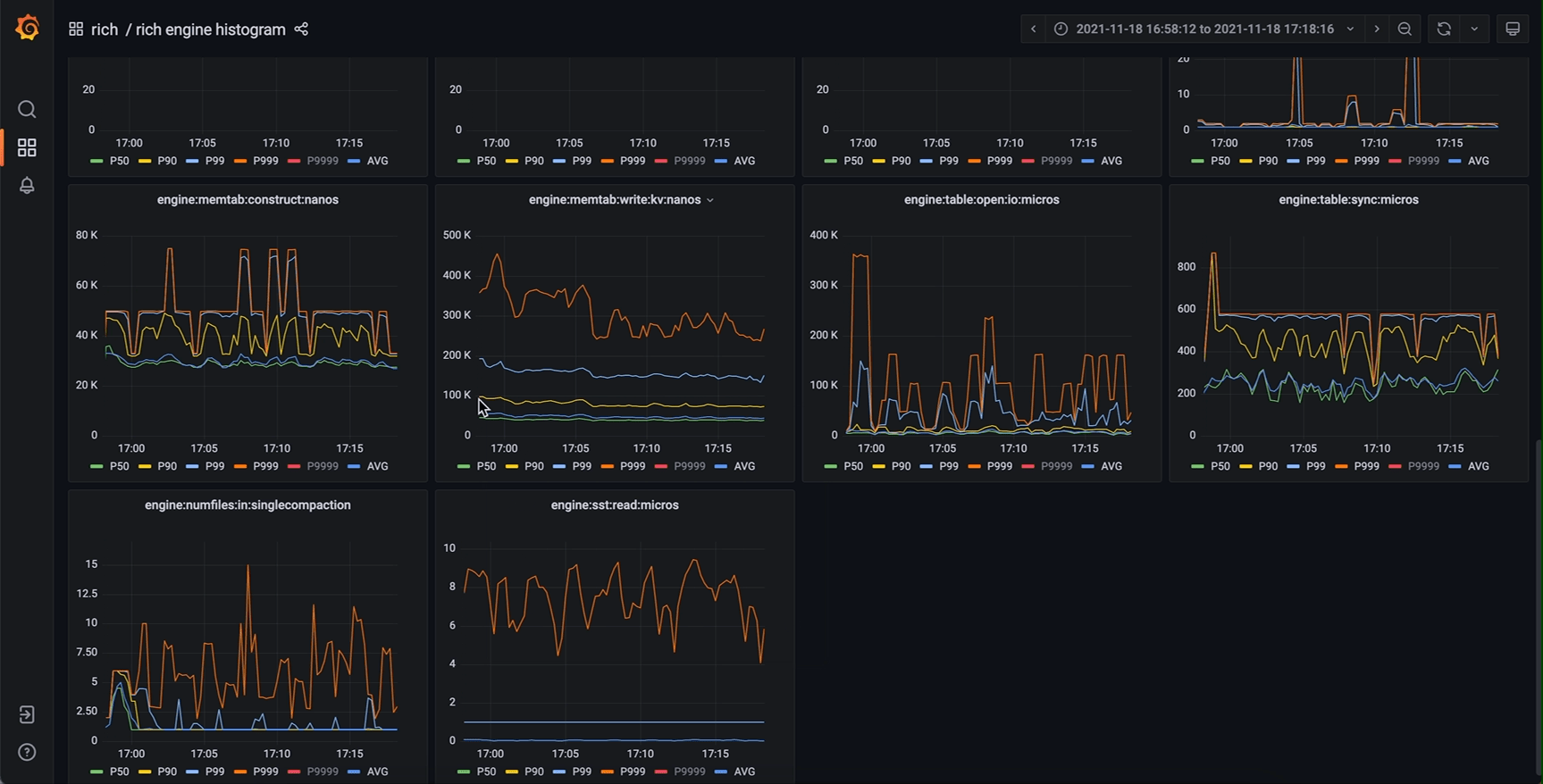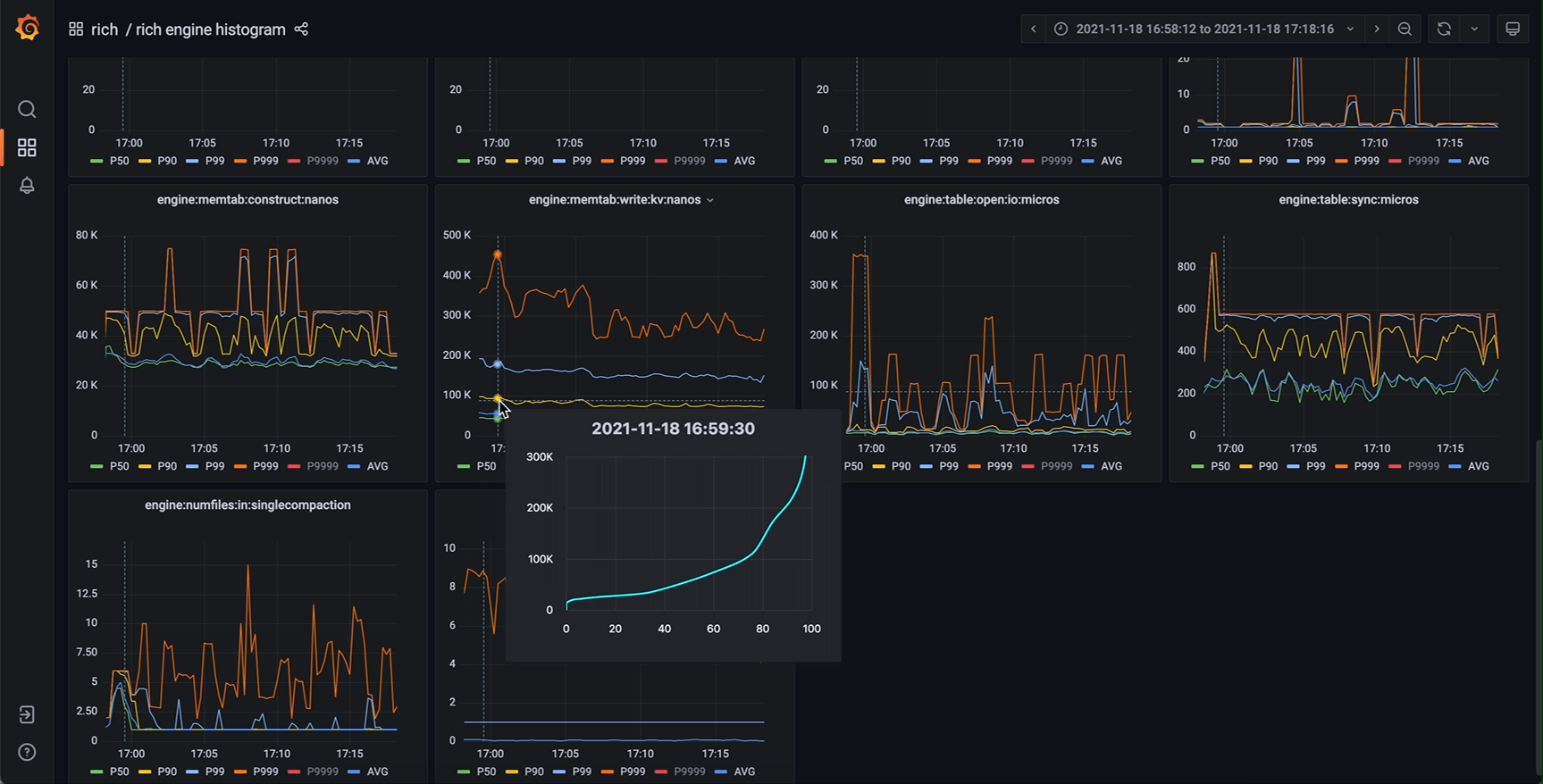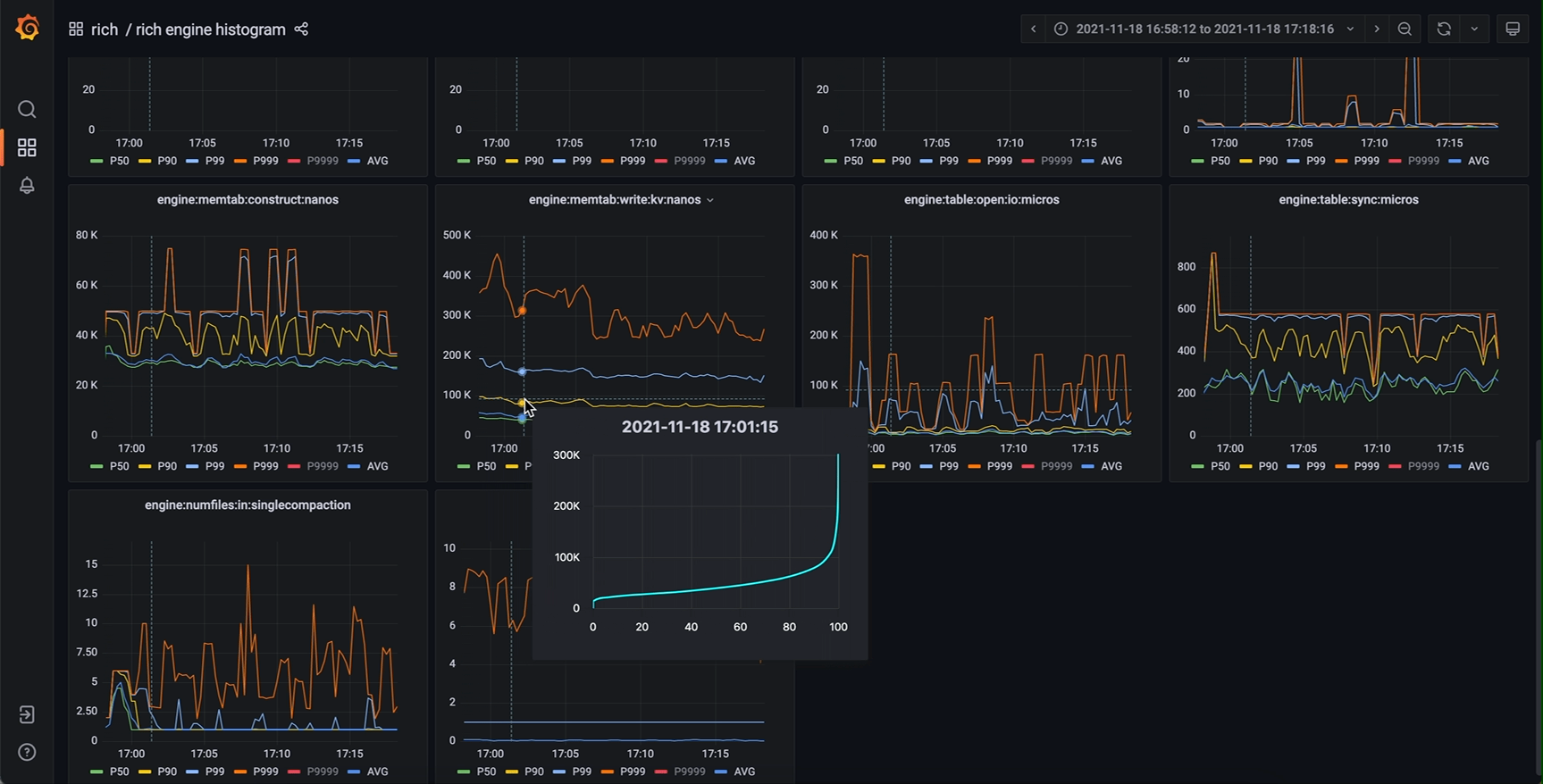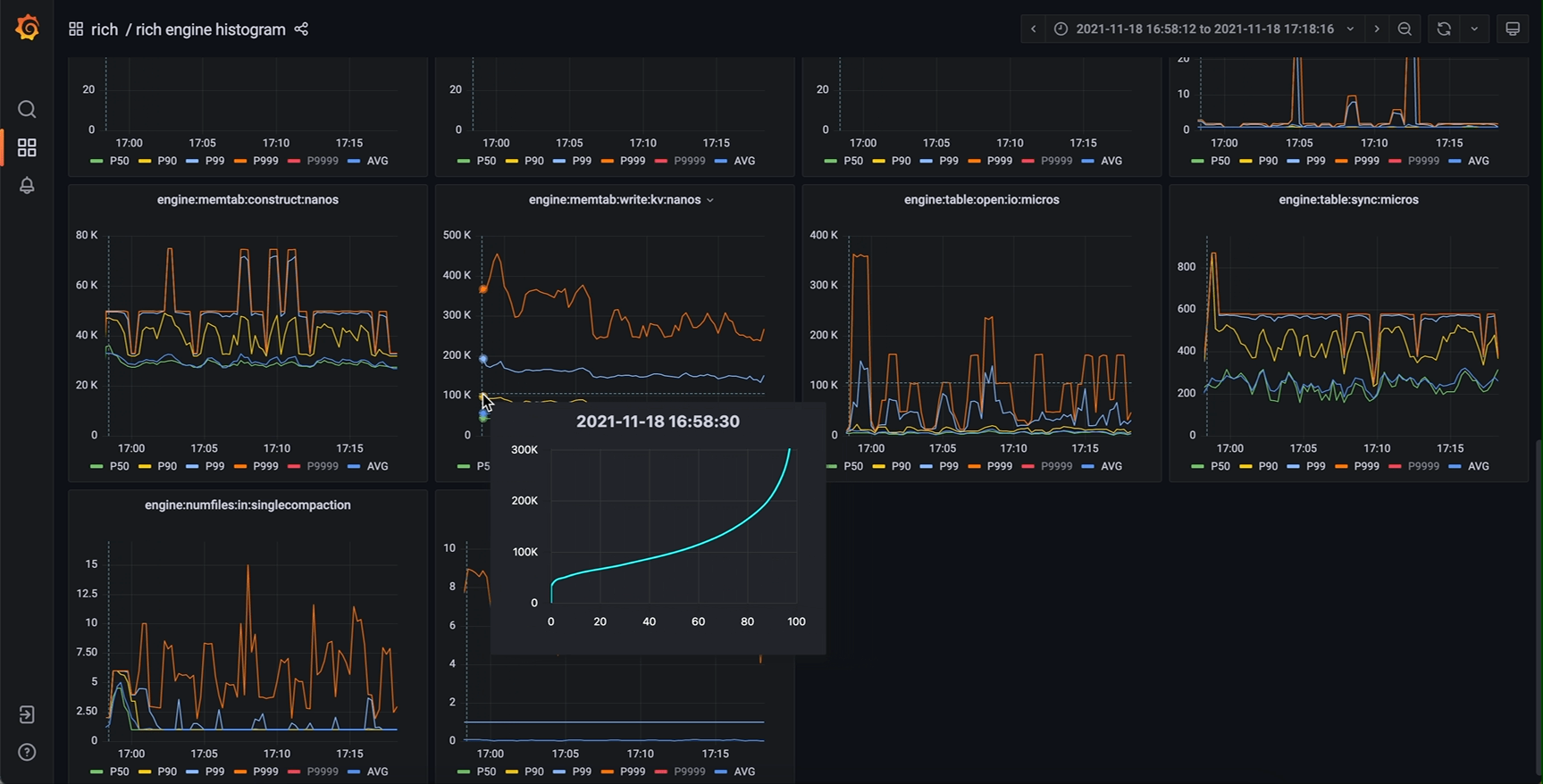
甚至还能添加第二y轴(对数坐标),对某些指标提供更好的效果